How do setup docker swarm in 5 minutes
Making Clustered-Pi into a real cluster
5 September 2022 by Kevin McAleer
What is docker Swarm?
Docker Swarm is a clustering and scheduling tool for Docker containers. Its native to Docker, meaning its built in without any additional software required.
A Swarm as the term suggests is a collection of computers that act together as one; for example you can specify that you want to have 3 replicas of a container running in your swarm and Docker Swarm will manage which nodes these run on and ensure that there are always 3 replicas running at any given moment. This means you can reboot the nodes of a clusters one at a time and Docker Swarm will ensure that the service is always running and available to end users without any downtime.
Docker Swarm is similar to Kubernetes, but simplier (with a fewer bells and whistles).
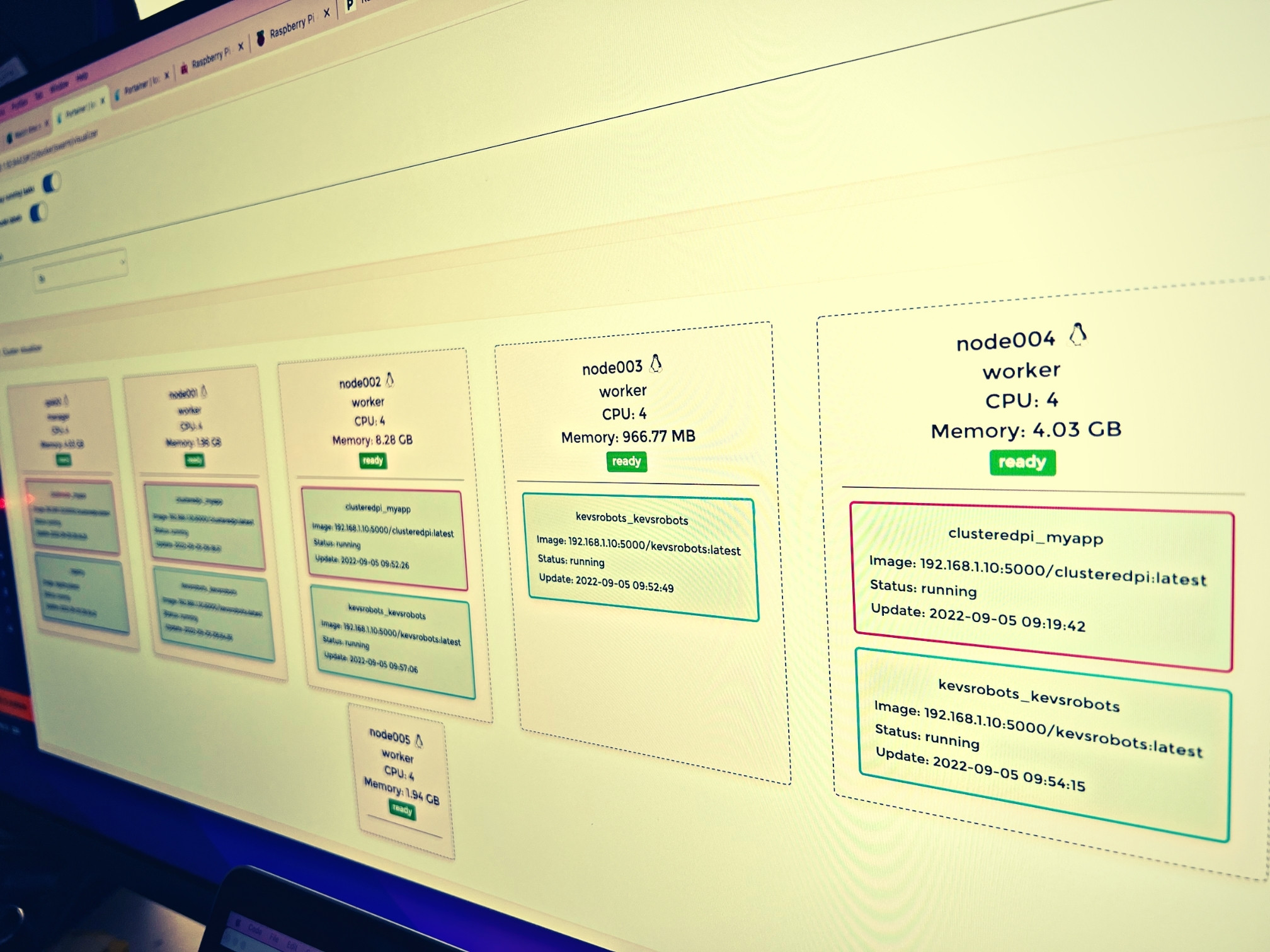
How to setup a Swarm
Setting up a swarm is very simple; simply type:
docker swarm init
and a new swarm will be created. You will get a message stating that the new Swarm has been created and a string of text to cut and paste to other docker nodes you wish to add to this Swarm.
Swarm Roles
There are essentially two roles for Docker Swarms: Manager and Worker.
Manager Role
The Manager role enables you to perform operations such as creating or removing services. The Manager can start and stop containers, update containers and scale the containers across the swarm.
Worker Role
The Worker role actually runs the containers and has its workload defined by the Manager Role. The Worker cannot issue management commands to the Swarm unless it is upgraded to a Manager role.
Services
A Service is like a Stack in the conventional Docker sense; it is a collection of containers that work together to provide a service to end users. For example a ‘weather dashboard’ service may consist of serveral containers; a grafana dashboard, influxdb database and node-red instance. These work together to provide the weather dashboard service to the end user.
Services can be scaled across nodes to enable High Availability (HA) and redundancy - meaning if one node goes down, another node is available to handle the workload.